Overview of Distributed Cloud GEO Redundancy¶
StarlingX Distributed Cloud Geo Redundancy configuration supports the ability to recover from a catastrophic event that requires subclouds to be rehomed away from the failed system controller site to the available site(s) which have enough spare capacity. This way, even if the failed site cannot be restored in short time, the subclouds can still be rehomed to available peer system controller(s) for centralized management.
In this configuration, the following items are addressed:
1+1 GEO redundancy
Active-Active redundancy model
Total number of subcloud should not exceed 1K
Automated operations
Synchronization and liveness check between peer systems
Alarm generation if peer system controller is down
Manual operations
Batch rehoming from alive peer system controller
Distributed Cloud GEO Redundancy Architecture¶
1+1 Distributed Cloud GEO Redundancy Architecture consists of two local high availability Distributed Cloud clusters. They are the mutual peers that form a protection group illustrated in the figure below:
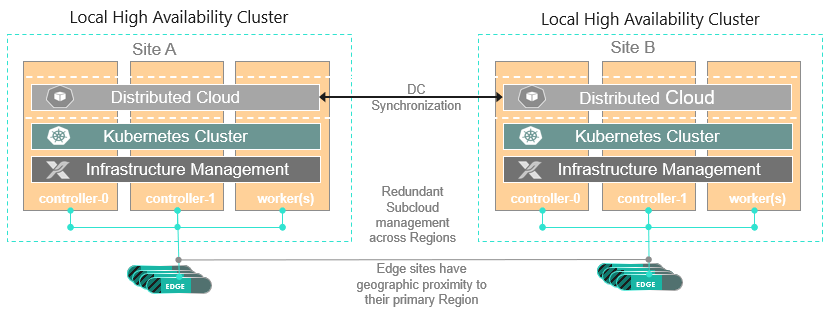
The architecture features a synchronized distributed control plane for geographic redundancy, where system peer instance is created in each local Distributed Cloud cluster pointing to each other via keystone endpoints to form a system protection group.
If the administrator wants the peer site to take over the subclouds where local system controller is in failure state, SPG needs to be created and subclouds need to be assigned to it. Then, a Peer Group Association needs to be created to link the system peer and SPG together. The SPG information and the subclouds in it will be synchronized to the peer site via the endpoint information stored in system peer instance.
The peer sites do health checks via the endpoint information stored in the system peer instance. If the local site detects that the peer site is not reachable, it will raise an alarm to alert the administrator.
If the failed site cannot be restored quickly, the administrator needs to initiate batch subcloud migration by performing migration on the SPG from the healthy peer of the failed site.
When the failed site has been restored and is ready for service, administrator can initiate the batch subcloud migration from the restored site to migrate back all the subclouds in the SPG for geographic proximity.
Protection Group A group of peer sites, which is configured to monitor each other and decide how to take over the subclouds (based on predefined SPG) if any peer in the group fails.
System Peer A logic entity, which is created in a system controller site. System controller site uses the information (keystone endpoint, credential) stored in the system peer for the health check and data synchronization.
Subcloud Secondary Deploy State This is a newly introduced state for a subcloud. If a subcloud is in the secondary deploy state, the subcloud instance is only a placeholder holding the configuration parameters, which can be used to migrate the corresponding subcloud from the peer site. After rehoming, the subcloud’s state will be changed from secondary to complete, and is managed by the local site. The subcloud instance on the peer site is changed to secondary.
Subcloud Peer Group Group of locally managed subclouds, which is supposed to be duplicated into a peer site as secondary subclouds. The SPG instance will also be created in peer site and it will contain all the secondary subclouds just duplicated.
Multiple SPGs are supported and the membership of the SPG is decided by administrator. This way, administrator can divide local subclouds into different groups.
SPG can be used to initiate subcloud batch migration. For example, when the peer site has been detected to be down, and the local site is supposed to take over the management of the subclouds in failed peer site, administrator can perform SPG migration to migrate all the subclouds in the SPG to the local site for centralized management.
Subcloud Peer Group Priority The priority is an attribute of SPG instance, and the SPG is designed to be synchronized to each peer sites in the protection group with different priority value.
In a Protection Group, there can be multiple System Peers. The site which owns the SPG with the highest priority (smallest value) is the leader site, which needs to initiate the batch migration to take over the subclouds grouped by the SPG.
Subcloud Peer Group and System Peer Association Association refers to the binding relationship between SPG and system peer. When the association between a SPG and system peer is created on the local site, the SPG and the subclouds in the group will be duplicated to the peer site to which the system peer in this association is pointing. This way, when the local site is down, the peer site has enough information to initiate the SPG based batch migration to take over the centralized management for subclouds previously managed by the failed site.
One system peer can be associated with multiple SPGs. One SPG can be associated with multiple system peers, with priority specified. This priority is used to decide which SPG has the higher priority to take over the subclouds when batch migration should be performed.
